practicing techie
tech oriented notes to self and lessons learned
Implementing Jersey 2 Spring integration
Posted by on 2014-02-08
Jersey is the excellent Java JAX-RS specification reference implementation from Oracle. Last year, when we were starting to build RESTful backend web services for a high-volume website, we chose to use the JAX-RS API as our REST framework and Spring framework for dependency injection. Jersey was our JAX-RS implementation of choice.
When the project was started JAX-RS API 2.0 specification was not yet released, and neither was Jersey 2.0. Since we didn’t see any fundamental deficiencies with JAX-RS 1.1, and because a stable Spring integration module existed for Jersey 1.1, we decided to go with the tried-and-true version instead of taking on the bleeding edge.
Still, I was curious to learn what could be gained by adopting the newer version, so I started looking at the JAX-RS 2 API on my free time and doing some prototyping with Jersey 2. I noticed that Jersey 2 lacked Spring framework integration that was available for the previous version. Studying the issue further, I found that the old Spring integration module would not be directly portable to Jersey 2. The reason was that Jersey 1 builds on a custom internal dependency injection framework while Jersey 2 had switched to HK2 for dependency injection. (HK2 is an interesting, light-weight dependency injection framework used in GlassFish.)
My original goals for Jersey-Spring integration were fairly simple:
inject Spring beans declared in application context XML into JAX-RS resource classes (using @Autowired annotation or XML configuration)
So, I thought I’d dig a bit deeper and started looking into Jersey source code. I was happy to notice that Jersey development was being done in an open and approachable manner. The source code was hosted on GitHub and updated frequently. After a while of digging, a high-level design for Jersey Spring integration started to take shape. It took quite some experimenting and many iterations before the first working prototype. At that point, being an optimist, I hoped I was nearly done and contacted the jersey-users mailing list to get feedback on the design and implementation. The feedback: add more use cases, provide sample code, implement test automation, sign Oracle Contributor Agreement 🙂 (The feedback, of course, was very reasonable from the Jersey software product point of view). So, while it wasn’t quite back to the drawing board, but at this point I realized the last mile was to be considerably longer than I had hoped for.
Eventually, though, the Jersey-Spring integration got merged in Jersey 2 code base in Jersey v2.2 release. The integration API is based on annotations and supports the following features:
- inject Spring beans into Jersey managed JAX-RS resource classes (using org.springframework.beans.factory.annotation.Autowired or javax.inject.Inject). @Qualifier and @Named annotations can be used to further qualify the injected instance.
- allow JAX-RS resource class instance lifecycle to be managed by Spring instead of Jersey (org.springframework.stereotype.Component)
- support different Spring bean injection scopes: singleton, request, prototype. Bean scope is declared in applicationContext.xml.
The implementation
Source code for the Jersey-Spring integration can be found in the main Jersey source repository:
https://github.com/jersey/jersey/tree/2.5.1/ext/spring3/src/main/java/org/glassfish/jersey/server/spring
Jersey-Spring integration consists of the following implementation classes:
org.glassfish.jersey.server.spring.SpringComponentProvider
This ComponentProvider implementation is registered with Jersey SPI extension mechanism and it’s responsible for bootstrapping Jersey 2 Spring integration. It makes Jersey skip JAX-RS life-cycle management for Spring components. Otherwise, Jersey would bind these classes to HK2 ServiceLocator with Jersey default scope without respecting the scope declared for the Spring component. This class also initializes HK2 spring-bridge and registers Spring @Autowired annotation handler with HK2 ServiceLocator. When being run outside of servlet context, a custom org.springframework.web.context.request.RequestScope implementation is configured to implement request scope for beans.
org.glassfish.jersey.server.spring.AutowiredInjectResolver
HK2 injection resolver that injects dependencies declared using Spring framework @Autowired annotation. HK2 invokes this resolver and asks it to resolve dependencies annotated using @Autowired.
org.glassfish.jersey.server.spring.SpringLifecycleListener
Handles container lifecycle events. Refreshes Spring context on reload and close it on shutdown.
org.glassfish.jersey.server.spring.SpringWebApplicationInitializer
A convenience class that helps the user avoid having to configure Spring ContextLoaderListener and RequestContextListener in web.xml. Alternatively the user can configure these in web application web.xml.
In addition to the actual implementation code, the integration includes samples and tests, which can be very helpful in getting developers started.
The JAX-RS specification defines its own dependency injection API. Additionally, Jersey supports JSR 330 style injection not mandated by the JAX-RS specification. Jersey-Spring integration adds support for Spring style injection. Both JAX-RS injection and Spring integration provide a mechanism for binding objects into a registry, so that objects can later be looked up and injected. If you’re using a full Java EE application server, such as Glassfish, you also have the option of binding objects via the CDI API. On non-Java EE environments it’s possible to use CDI by embedding a container implementation such as Weld. Yet another binding method is to use Jersey specific API. The test code includes a JAX-RS application class that demonstrates how this can be done.
Modifying Jersey-Spring
If you want to work on Jersey-Spring, you need to check out Jersey 2 code base and build it. That process is rather easy and well documented:
https://jersey.java.net/documentation/2.5.1/how-to-build.html
You simply need to clone the repository and build the source. The build system is Maven based. You can also easily import the code base into your IDE of choice (tried it with IDEA 12, Eclipse 4.3 and NetBeans 8.0 beta) using its Maven plugin. I noticed, however, that some integration tests failed with Maven 3.0, and I had to upgrade to 3.1, but apart from that there weren’t any issues.
After building Jersey 2 you can modify the Spring integration module, and build only the changed modules to save time.
Tests
Jersey-Spring integration tests have been built using Jersey test framework and they’re run under the control of maven-failsafe-plugin. Integration tests consist of actual test code and a JAX-RS backend webapp that the tests exercise. The backend gets deployed into an external Jetty servlet container using jetty-maven-plugin. Jersey-Spring tests can be executed separately from the rest of the tests. Integration tests can be found in a separate Maven submodule here:
https://github.com/jersey/jersey/tree/2.5.1/tests/integration/spring3
In addition to demonstrating the basic features of Jersey-Spring, the tests show how to use different Spring bean scopes: singleton, request, prototype. The tests also exhibit using a JAX-RS application class for registering your own dependencies in the container, in different scopes.
Conclusions
I think the JAX-RS 2.0 API provides a nice and clean way of implementing RESTful interfaces in Java. Development of the Jersey JAX-RS reference implementation is being conducted in an open and transparent manner. Jersey also has a large and active user community.
As noted by Frederick Brooks, Jr.: “All programmers are optimists”. It’s often easy to underestimate the amount of work required to integrate code with a relative large and complex code base, and in particular when you need to mediate between multiple different frameworks (in this case Jersey, HK2, Spring framework). Also, though Jersey has pretty good user documentation, I missed high-level architectural documentation on the design and implementation. A lot of poking around was needed to be able to identify the correct integration points. Fortunately, the Jersey build system is pretty easy to use and allows building only selected parts, which makes experimenting and the change-build-test cycle relatively fast.
Both Jersey and Spring framework provide a rich set of features and you can use them together in a multitude of ways. Jersey-Spring integration in it’s current form covers a couple of basic integration scenarios between the two. If you find that your particular scenario isn’t supported, join the jersey-users mailing list to discuss it. You can also just check out the code, implement your changes and contribute them by submitting a pull request on GitHub.
Building a beacon out of Pi
Posted by on 2013-11-07
Building a beacon out of Pi
iBeacon is, to quote Wikipedia, an indoor positioning system that Apple calls “a new class of low-powered, low-cost transmitters that can notify nearby iOS 7 devices of their presence. The technology is not, however, restricted to iOS devices and can currently also be used with Android devices. Many people are predicting it will change retail shopping.
At it’s core, the technology allows proximity sensing so, that a device can alert a user when moved from or to close proximity of a peer device. In a typical use case a “geo fence” is established around a stationary device (i.e. “beacon”) and mobile devices carried by users issue alerts when crossing the fence to either enter or exit the region.
After Apple’s WWDC 2013 conference we’ve seen quite a bit of a buzz about iBeacon. Interestingly, the underlying technology is based on the Bluetooth Proximity profile specification ratified in 2011. Though a lot of the buzz has been associated with Apple, the company is not attributed as a contributor to the original specification. Also, Apple is yet to reveal what it plans to do exactly with iBeacon.
A few other companies are planning to bring iBeacon compatible beacons to the market, but the beacons aren’t shipping, yet. So, if you want to start developing software right now you have to resort to other solutions. One option is to use a Bluetooth LE (BLE) capable device, equipped with the right software, as a beacon. For example BLE capable iOS devices, can act as beacons with the AirLocate application. So, if you have e.g. a new iPhone 5 to spare, you can make it into a beacon very easily. Another option is to build a beacon yourself, since iBeacons are based on standard Bluetooth LE proximity profile. A company called Radius Networks has published an article about building a beacon, so I decided to try this out.
Beacon BOM
The bill of materials for the beacon was pretty simple
- Raspberry Pi + memory card + power cord
- a USB Bluetooth 4.0 LE dongle
Additionally, I bought the following items to make installation easier:
- a USB SD card reader
- HDMI display cable
- USB hub
beacon bill-of-materials
Unfortunately, Radius was using IOGEAR GBU521 Bluetooth dongle which I couldn’t find at any of the local electronics shops. USB Bluetooth dongles aren’t very expensive, however, and since there aren’t many Bluetooth chipsets on the market, I decided to experiment a bit and buy two different dongles to try out. These were the Asus USB-BT400 and TeleWell Bluetooth 4.0 LE + EDR.
Operating system deployment
Some vendors sell memory cards with pre-installed OS for Raspberry Pi, but I couldn’t find one of those either at my local electronics shop, so I bought a blank memory card and a USB-based SD card reader, just in case. The SD card reader proved handy because it turned out the card didn’t work with the built-in reader on my MacBook Pro. Installing the Raspbian (2013-09-25-wheezy) Linux distribution was fairly straightforward using the instructions on Embedded Linux Wiki (RPi Easy SD Card Setup). The only notable issue was that on Mac OS X writing the OS image to the card was a lot faster (~ 4 min. vs. ~ 30 min.) using the raw disk device instead of the buffered one. Another issue was that the memory card disk had to be unmounted using diskutil, not ejecting it through Mac OS X Finder.
After installing the OS image on the SD card it was time to see if the thing would boot. Unfortunately, I only had a VGA monitor and no suitable HDMI-VGA adapters , so I wasn’t able to make a console connection with the Pi. Being eager to see if everything worked so far, I decided to connect the Pi to a wireless access point and power it up. After a few moments, I noticed that RasPi had acquired an IP address from the AP’s DHCP server and I was able to log in to the Pi via SSH using the default credentials. So, no console whatsoever was required to set up the Pi!
Being a Java developer, I was happy to notice that Raspbian came with a fairly recent Java Standard Edition 7 installation by default. The latest Java 8 build is also available for Raspbian.
Building the Bluetooth stack
Once the basic OS setup was done, I had to compile the BlueZ Linux Bluetooth stack which, proved to be a rather simple matter of installing the compile-time pre-requisites through RasPi package management (apt-get):
libusb-dev libdbus-1-dev libglib2.0-dev libudev-dev libical-dev libreadline-dev
and then configuring the source and building it. I used BlueZ version 5.10, which was the latest official version at the time.
After compiling the BlueZ Bluetooth protocol stack it was time to test if the Bluetooth dongles I had bought were working. Running hciconfig I noticed that the Telewell dongle was being detected, while the Asus wasn’t. During further testing it became clear that the Pi’s signal wasn’t being picked up by a demo app on an iPad. More research showed that though the TeleWell dongle did support Bluetooth 4.0 LE, it didn’t officially support the required proximity profile. After yet more googling, I found that the Asus dongle seemed to include the same Broadcom BCM20702 (A0) chipset as the IOGEAR one used by Radius Networks. However, the dongle wasn’t being detected because Asus has a vendor specific USB device ID for it that wasn’t known by the Raspbian kernel. The solution for this issue was to add the device ID in the kernel source (credit to linux-bluetooth mailing list), rebuild and install the newly built kernel.
Compiling the Linux kernel
Compiling the Linux kernel is a very time-consuming task, particularly on a resource constrained environment such as the Raspberry Pi. Fortunately, it’s possible to set up a cross-compiler environment on a more powerful system to speed things up. Again, the Embedded Linux Wiki proved to be a great resource with this task (RPi Kernel Compilation). Though, you can install a x86 / Mac OS X ⇒ ARM / Linux cross-compilation environment, I thought I’d try to go for an, arguably, more mainstream choice and set up my cross-compiler environment on a Linux Mint 15 Xfce guest virtual machine. The required packages were again available via apt-get:
gcc-arm-linux-gnueabi libncurses-dev
Additionally, Git had to be installed to be able to fetch the Raspberry Pi kernel source, build tools and firmware.
Kernel compilation for Raspberry Pi is a bit different than compiling a standard kernel for a server class machine, and is done using the following procedure:
- fetch Raspberry Pi Linux kernel source, compiler tools and firmware
- set up environment variables for the compilation
- configure the kernel source (using a config file from the Pi)
- build kernel and modules
- package up the kernel, modules and firmware
- deploy kernel, modules and firmware to Pi
- reboot Pi (with fingers crossed)
Fortunately, I was able to produce and deploy a working kernel build and the Pi booted up with the fresh kernel. This time, hciconfig showed that the kernel and the Bluetooth stack were able to detect the Asus Bluetooth dongle.
Testing the beacon
There are a couple of mobile applications available that can be used for verifying that a beacon is functioning properly. iBeacon Locate is available in Google play store for Android 4.3+ users and Beacon Toolkit in Apple App Store for iOS 7.0+ users. Both applications require that the device supports Bluetooth BLE.
Sample code demonstrating how to read beacon signals is also available from multiple sources, including the AirLocate application, Apple WWDC 2013 and android-ibeacon-service. AirLocate e.g. is a complete sample app that you can build, modify and install on your iOS device, provided that you have an Apple iOS developer certificate.
I was able to pick up the Raspberry Pi’s beacon signal using AirLocate on iOS and iBeacon Locate on Android. There were some problems with the sample apps, when I configured the beacon to use a custom device UUID instead of an Apple demo UUID: the demo apps failed to detect the beacon when using custom a UUID. A custom application was, however, able to detect the beacon also with a custom UUID.
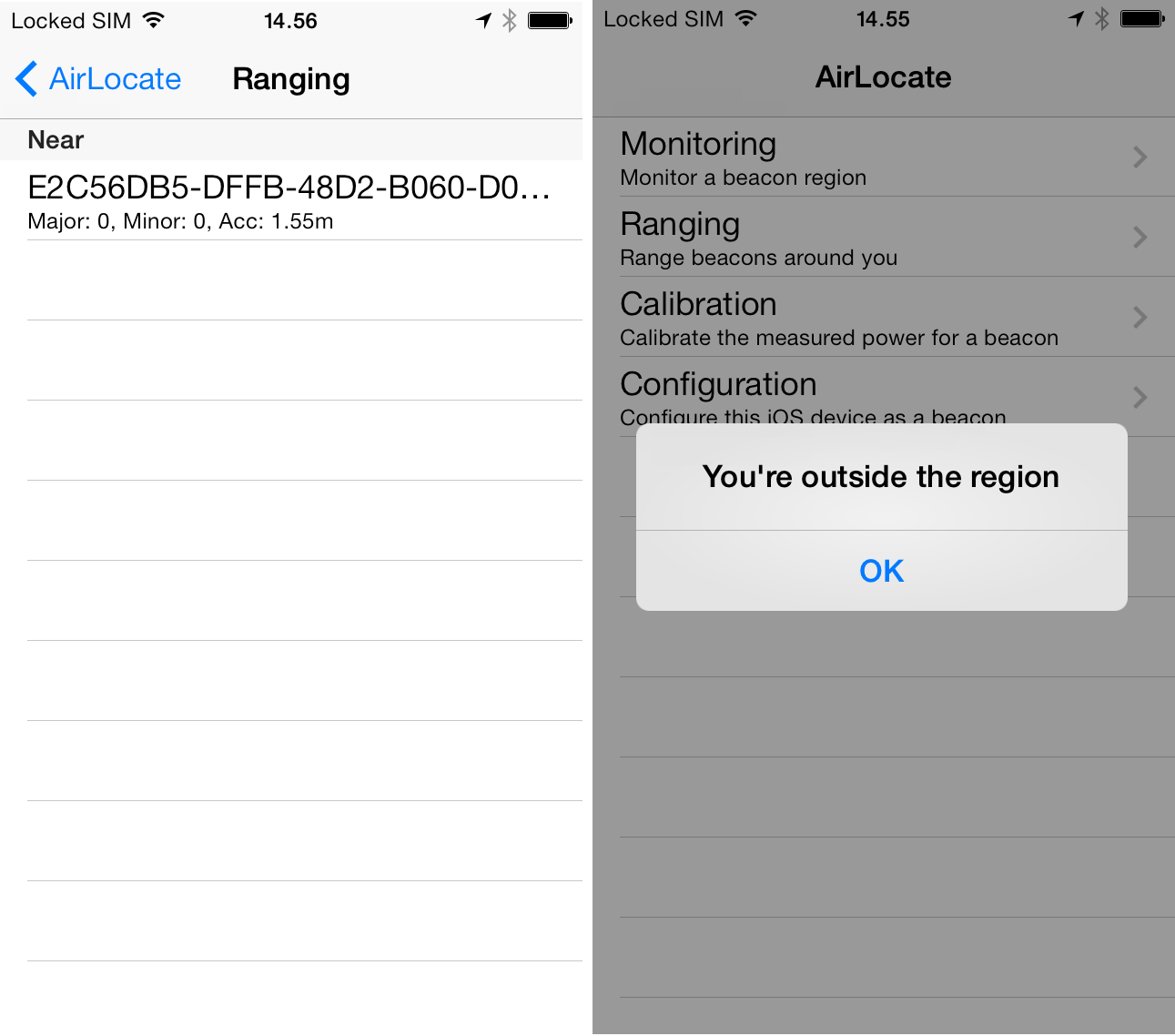
beacon ranging and proximity sensing alert
Next, I’ll have to experiment a bit more with proximity sensing accuracy, notification event delay and how different physical space topologies and interference affect proximity sensing. Also, a demo app should be developed to simulate proximity alerts in the context of a real use case.
Init scripts
Once Pi beacon was running fine, the last thing was to make the beacon automatically turn on at boot. For this I studied the existing init scripts to learn what kind of metadata is required to be able to manage the “service” using update-rc.d command. I also separated the configuration parameters in a separate file (/etc/default/ibeacon.conf) from the init script.
Final thoughts
iBeacon is based on standard Bluetooth 4.0 LE proximity profile that is not Apple proprietary technology. The technology works currently on newer iOS and Android devices, and these operating systems include APIs required to detect beacon signals. iBeacon has many interesting use cases for indoor positioning, including but not limited to, retail shopping and analytics. It’s still an emerging technology and I’m sure we’ll see it applied in many unexpected contexts in the future.
The Raspberry Pi is a device platform with intriguing possibilities. Traditionally embedded software development and server-side software development have required very different skill sets. Raspberry Pi demonstrates how the embedded platforms have evolved significantly during the last few years in terms of hardware capacity as well as software platform maturity. Consider e.g. the following points:
- the system has “standard” support for Java as well as many other popular language runtimes, making it possible to develop software using desktop or server-side development skills and tools
- hardware capacity is gaining on low-end server-class machines in terms of memory, CPU and storage capacity
- the OS and other software can be updated over the network using update manager tools instead of having to flash firmware
- it’s based on a standard Linux environment
- the system supports remote management over secure terminal connection
With the high end embedded platforms, such as the Raspberry Pi, similar tools and techniques can be used for developing software on both platforms, so from a development and maintenance point of view these platforms are converging. This creates fascinating opportunities for software developers who don’t have a traditional embedded development skill set.
Practical NoSQL experiences with Apache Cassandra
Posted by on 2013-07-13
Most of the backend systems I’ve worked with over the years have employed relational database storage in some role. Despite many application developers complaining about RDBMS performance, I’ve found that with good design and implementation a relational database can actually scale a lot further than developers think. Often software developers who don’t really understand relational databases tend to blame the database for being a performance bottleneck, even if the root cause could actually be traced to bad design and implementation.
That said, there are limits to RDBMS scalability and it can become a serious issue with massive transaction and data volumes. A common workaround is to partitioning application data based on a selected criteria (functional area and/or selected property of entities within functional area) and then distributing data across database server nodes. Such partitioning must usually be done at the expense of relaxing consistency. There are also plenty of other use cases for which relational databases in general, or the ones that are available to you, aren’t without problems.
Load-balancing and failover are sometimes difficult to achieve even on a smaller scale with relational databases, especially if you don’t have the option to license a commercial database clustering option. And even if you can, there are limits to scalability. People tend to workaround these problems with master-slave database configurations, but they can be difficult to set up and manage. This sort of configuration will also impact data consistency if master-slave replication is not synchronous, as is often the case.
When an application also requires a dynamic or open-ended data model, people usually start looking into NoSQL storage solutions.
This was the path of design reasoning for a project I’m currently working on. I’ve been using Apache Cassandra (v1.2) in a development project for a few months now. NoSQL databases come in very different forms and Cassandra is often characterized as a “column-oriented” or “wide-row” database. With the introduction of the Cassandra Query Language (CQL) Cassandra now supports declaring schema and typing for your data model. For the application developer, this feature brings the Cassandra data model somewhat closer to the relational (relations and tuples) model.
NoSQL design goals and the CAP theorem
NoSQL and relational databases have very different design goals. It’s important for application developers to understand these goals because in practice they guide and dictate the set of feasible product features.
ACID transaction guarantees provide a strong consistency model around which web applications have traditionally been designed. When building Internet-scale systems developers came to realize that strong consistency guarantees come at a cost. This was formulated in Brewer’s CAP theorem, which in its original form stated that a distributed system can only achieve two of the following properties:
- consistency (C) equivalent to having a single up-to-date copy of the data;
- high availability (A) of that data (for updates); and
- tolerance to network partitions (P).
The “2 of 3” formulation was later revised somewhat by Brewer, but this realization led developers to consider using alternative consistency models, such as “Basically Available, Soft state, Eventual consistency” or BASE, in order to trade off strong consistency guarantees for availability and partition tolerance, but also scalability. Promoting availability over consistency became a key design tenet for many NoSQL databases. Other common design goals for NoSQL databases include high performance, horizontal scalability, simplicity and schema flexibility. These design goals were also shared by Cassandra founders, but it was also designed to be CAP-aware, meaning the developer is allowed to tune the tradeoff between consistency and latency.
BASE is a consistency model for distributed systems that does not require a NoSQL database. NoSQL databases that promote the BASE model also encourage applications to be designed around BASE. Designing a system that uses BASE consistency model can be challenging from technical perspective, but also because relaxing consistency guarantees will be visible to the users and requires a new way of thinking from the product owner, who traditionally are accustomed to thinking in terms of a strong consistency model.
Data access APIs and client libraries
One of the first things needed when starting to develop a Java database application is a database client library. With most RDBMS products this is straightforward: JDBC is the defacto low-level database access API, so you just download a JDBC driver for that particular database and configure your higher level data access API (e.g. JPA) to use that driver. You get to choose which higher level API to use, but there’s usually only a single JDBC driver vendor for a particular database product. Cassandra on the other hand currently has 9 different clients for Java developers. These clients provide different ways of managing data: some offer an object-relational -mapping API, some support CQL and others provide a lower level (e.g. Thrift based) APIs.
Data in Cassandra can be accessed and managed using an RPC-style (Thrift based) API, but Cassandra also has a very basic query language called CQL that resembles SQL syntactically to some extent, but in many cases the developer is required to have a much deeper knowledge of how the storage engine works below the hood than with relational databases. The Cassandra community recommended API to use for new projects using Cassandra 1.2 is CQL 3.
Since Cassandra is being actively developed, it’s important to pick a client whose development pace matches that of the server. Otherwise you won’t be able to leverage all the new server features in your application. Because Cassandra user community is still growing, it’s good to choose a client with an active user community and existing documentation. Astyanax client, developed by Netflix, currently seems to be the most widely used, production-ready and feature complete Java client for Cassandra. This client supports both Thrift and CQL 3 based APIs for accessing the data. DataStax, a company that provides commercial Cassandra offering and support, is also developing their own CQL 3 based Java driver, which recently came out of beta phase.
Differences from relational databases
Cassandra storage engine design goals are radically different from those of relational databases. These goals are inevitably reflected in the product and APIs, and IMO neither can nor should be hidden from the application developer. The CQL query language sets expectations for many developers and may make them assume they’re working with a relational database. Some important differences to take note of that may feel surprising from an RDBMS background include:
- joins and subqueries are not supported. The database is optimized for key-oriented access and data access paths need to be designed in advance by denormalization. Apache Solr, Hive, Pig and similar solutions can be used to provide more advanced query and join functionality
- no integrity constraints. Referential and other types of integrity constraint enforcement must be built into the application
- no ACID transactions. Updates within a single row are atomic and isolated, but not across rows or across entities. Logical units of work may need be split and ordered differently than when using RDBMS. Applications should be designed should to be designed for eventual consistency
- only indexed predicates can be used in query statements. An index is automatically created for row keys, indexes in other column values can be created as needed (except currently for collection typed columns). Composite indexes are not supported. Solr, Hive etc. can be used to address these limitations.
- sort criteria needs to be designed ahead. Sort order selection is very limited. Rows are sorted by row key and columns by column name. These can’t be changed later. Solr, Hive etc. can be used to address these limitations.
Data model design is a process where developers will encounter other dissimilarities compared to the RDBMS world. For Cassandra, the recommended data modeling approach is the opposite of RDBMS: identify data access patterns, then the model data to support those access patterns. Data independence is not a primary goal and developers are expected to understand how the CQL data model maps to storage engine’s implementation data structures in order to make optimal use of Cassandra. (In practice, full data independence can be impossible to achieve with high data volume RDBMS applications as well). The database is optimized for key-oriented data access and data model must be denormalized. Some aspects of the application that can be easily modified or configured at runtime in relational databases are design time decisions with Cassandra, e.g. sorting.
A relational application data model typically stores entities of a single type per relation. The Cassandra storage engine does not require that rows in a column family contain the same set of columns. You can store data about entirely unrelated entities in a single column family (wide rows).
Row key, partition key and clustering column are data modeling concepts that are important to understand for the Cassandra application developer. The Cassandra storage engine uniquely identifies rows by row key and keys provide the primary row access path. A CQL single column primary key maps directly to a row key in the storage engine. In case of a composite primary key, the first part of the primary key is used as the row key and partition key. The remaining parts of a composite primary key are used as clustering columns.
Row key and column name, along with partitioner (and comparator) algorithm selection have important consequences for data partitioning, clustering, performance and consistency. Row key and partitioner control how data is distributed among nodes in the database cluster and ordered within a node. These parameters also determine whether range scanning and sorting is possible in the storage engine. Logical rows with the same partition key get stored as a single, physical wide row, on the same database node. Updates within a single storage engine row are atomic and isolated, but not across rows. This means that your data model design determines which updates can be performed atomically. Columns within a row are clustered and ordered by the clustering columns, which is particularly important when the data model includes wide rows (e.g. time-series data).
When troubleshooting issues with an application, it’s often very important to be able to study the data in the storage engine using ad-hoc queries. Though Cassandra does support ad-hoc CQL queries, the supported query types are more limited. Also, the database schema changes, data migration and data import typically require custom software development. On the other hand, schema evolution has traditionally been very challenging with RDBMS when large data volumes have been involved.
Cassandra supports secondary indexes, but applications are often designed to maintain separate column families that support looking up data based on a single or multiple secondary access criteria.
One of the interesting things I noticed about Cassandra was that it has really nice load-balance and failover clustering support that’s quite easy to setup. Failover works seamlessly and fast. Cassandra is also quite lightweight and effortless to set up. Data access and manipulation operation performance is extremely fast in Cassandra. The data model is schema-flexible and supports use cases for which RDMBS usually aren’t up to the task e.g. storing large amounts of time-series data with very high performance.
Conclusions
Cassandra is a highly available, Internet-scale NoSQL database with design goals that are very different from those of traditional relational databases. The differences between Cassandra and relational databases identified in this article should each be regarded as having pros and cons and be evaluated in the context of the your problem domain. Also, using NoSQL does not exclude the use of RDBMS – it’s quite common to have a hybrid architecture where each database type is used in different use cases according the their strengths.
When starting their first NoSQL project, developers are likely to enter new territory and have their first encounters with related concepts such as big data and eventual consistency. Relational databases are often associated with strong consistency, whereas NoSQL systems are associated with eventual consistency (even though the use of a certain type of database doesn’t imply a particular consistency model). When moving from the relational world and strong consistency to the NoSQL world the biggest mind shift may be in understanding and architecting an application for eventual consistency. Data modeling is another area where a new way of design thinking needs to be adopted.
Cassandra is a very interesting product with a wide range of use cases. I think it’s particularly well suited database option for the following use cases:
- very large data volumes
- very large user transaction volumes
- high reliability requirements for data storage
- dynamic data model. Data model may be semi structured and expected see significant changes over time
- cross datacenter distribution
It is, however, very different from relational databases. In order to be able to make an informed design decision on whether to use Cassandra or not, a good way to learn more is to study the documentation carefully. Cassandra development is very fast paced, so many of the documents you may find could be outdated. There’s no substitute for hands-on experience, though, so you should do some prototyping and benchmarking as well.
Java VM Options
Posted by on 2013-06-15
Some of the more frequently used Java HotSpot VM Options have been publicly documented by Oracle.
Of those flags the following are the ones I tend to find most useful for server-side Java applications:
- -XX:+UseConcMarkSweepGC – select garbage collector type
- -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=$APP_HOME_DIR – when an out-of-memory error occurs, dump heap
- -XX:OnOutOfMemoryError=<command_for_processing_out_of_memory_errors> – execute user configurable command when an out-of-memory error occurs
- -XX:OnError=<command_for_processing_unexpected_fatal_errors> – execute user configurable command when an unexpected error occurs
- -XX:+PrintGCDetails -XX:+PrintGCTimeStamps – increase garbase collection logging
- -Xloggc:$APP_HOME_DIR/gc.log – log garbage collection information to a separate log file
- -XX:-UseGCLogFileRotation -XX:GCLogFileSize=<max_file_size>M -XX:NumberOfGCLogFiles=<nb_of_files> – set up log rotation for garbage collection log
Occasionally, the following might also be helpful to gain more insight into what the GC is doing:
- -XX:PrintHeapAtGC
- -XX:PrintTenuringDistribution
Oracle documentation covers quite a few HotSpot VM flags, but every once in a while you bump into flags that aren’t on the list. So, you begin to wonder if there’re more JVM options out there.
And, in fact, there’s a lot more as documented by this blog entry: The most complete list of -XX options for Java JVM
That list is enough to make any JVM application developer stand in awe 🙂
There’s enough options to shoot yourself in the foot, but you should avoid the temptation of employing each and every option.
Most of the time it’s best to use only the one’s you know are needed. JVM options and their default values tend to change from release to release, so it’s easy to end up with a huge list of flags that suddenly may not be required at all with a new JVM release, or worse, may even result in conflicting or erroneous behavior. The implications of some of the options, the GC one’s in particular, and the way that related options interact with each other may sometimes be difficult. Using a minimal list of options is easier to understand and maintain. Don’t just copy-paste options from other applications without really understanding what they’re for.
So, what’re your favorite options?
Mine would probably be -XX:SelfDestructTimer 😉
(No, there really is such an option and it does work)
Advanced PostgreSQL features
Posted by on 2013-05-12
Nearly all the server-side development projects I’ve worked in over the years have stored at least part of their data in a relational database system. Even the systems using NoSQL storage have included a RDBMS in some form, whether local to a single subsystem or in a large role. In some cases the RDBMS systems have been proprietary, but increasingly they’ve been open source projects.
I’ve been using PostgreSQL in projects with RDBMS storage requirements on and off over the years. It has often impressed me with its depth of support for the SQL standard as well as wide range of non-standard extension features. With other widely used OSS RDBMS engines, I’ve often noticed that while the database claims to support feature X on paper, it only supports a subset. And then there’s a list of limitations you need to account for. Typically those limitations are something you wouldn’t expect, so they come as a surprise. Subqueries and joins are one such feature.
With PostgreSQL, I haven’t yet found a case where the database wouldn’t be able to handle a SQL standard subquery or join statement. Having an item such as comprehensive support for SQL subqueries and joins in a database product feature list may not look particularly appealing, it may even raise some suspicions. But from a developer point of view I find this “feature” a very important one, perhaps even one of PostgreSQL’s biggest selling points compared to some of it’s OSS competitors. PostgreSQL has many other advanced features that are interesting for application developers.
Common table expressions and hierarchic queries
Common table expressions or CTE is a handy standard SQL feature that allows you to split a query statement into distinct parts where results of each part will appear as a table, so you can reference the intermediate results in other parts of the statement, possibly several times. This can help make query statements more maintainable, but it also helps optimize queries in some cases, since CTE expressions are performed only once per statement execution.
In addition to allowing subquery factoring, CTE can process data as hierarchical. With small amounts of data and relatively shallow hierarchies you can implement hierarchical queries simply using joins, but this workaround may not be acceptable in all cases. A CTE hierarchical query makes it possible to process arbitrarily deep hierarchies with just one query.
Here’s an example how you can get a list of subtasks in an arbitrarily deep task tree along with path information for each task. Including path information will make it easier to build a graph representation on the receiving end.
mydb=> WITH RECURSIVE task_tree (id, name, parent_id, depth, path) AS (
mydb(> SELECT id, name, parent_id, 1, ARRAY[t.id]
mydb(> FROM task t WHERE t.id = 1
mydb(> UNION ALL
mydb(> SELECT s.id, s.name, s.parent_id, tt.depth + 1, path || s.id
mydb(> FROM task s, task_tree tt WHERE s.parent_id = tt.id
mydb(> )
mydb-> SELECT * FROM task_tree
mydb-> ORDER BY depth ASC;
id | name | parent_id | depth | path
----+-------------+-----------+-------+-------------
1 | task1 | | 1 | {1}
4 | task1-1 | 1 | 2 | {1,4}
5 | task1-2 | 1 | 2 | {1,5}
6 | task1-3 | 1 | 2 | {1,6}
13 | task1-3-1 | 6 | 3 | {1,6,13}
14 | task1-3-1-1 | 13 | 4 | {1,6,13,14}
(6 rows)
PostgreSQL also has an extension module that allows handling hierarchic data in a less verbose, but non-standard manner:
mydb=> SELECT * FROM connectby('task', 'id', 'parent_id', '1', 0, '/')
mydb-> AS t(id BIGINT, parent_id BIGINT, level INT, branch TEXT);
id | parent_id | level | branch
----+-----------+-------+-----------
1 | | 0 | 1
4 | 1 | 1 | 1/4
5 | 1 | 1 | 1/5
6 | 1 | 1 | 1/6
13 | 6 | 2 | 1/6/13
14 | 13 | 3 | 1/6/13/14
(6 rows)
Aggregates and window functions
SQL GROUP BY lets you calculate aggregates of data over a single or multiple columns in a result set. The clause, however, can only aggregate over a single grouping, so it wouldn’t be possible e.g. to get calculate average salaries over departments and locations in a single query. Another limitation is that only aggregated data is returned and detail data is not preserved, so you can’t get both the detail records and aggregates using a single query.
Window functions make it possible to get both. Here’s how to calculate employee salary aggregates over several different groupings while preserving the detail records:
mydb=> SELECT depname, location, empno, salary, mydb-> AVG(salary) OVER (PARTITION BY depname) avgdept, mydb-> SUM(salary) OVER (PARTITION BY depname) sumdept, mydb-> AVG(salary) OVER (PARTITION BY location) avgloc, mydb-> RANK() OVER (PARTITION BY depname ORDER BY salary DESC, empno) AS pos mydb-> FROM empsalary; depname | location | empno | salary | avgdept | sumdept | avgloc | pos -----------+----------+-------+--------+-----------------------+---------+-----------------------+----- develop | fi | 8 | 6000 | 5020.0000000000000000 | 25100 | 4550.0000000000000000 | 1 develop | se | 10 | 5200 | 5020.0000000000000000 | 25100 | 4950.0000000000000000 | 2 develop | fi | 11 | 5200 | 5020.0000000000000000 | 25100 | 4550.0000000000000000 | 3 develop | fi | 9 | 4500 | 5020.0000000000000000 | 25100 | 4550.0000000000000000 | 4 develop | fi | 7 | 4200 | 5020.0000000000000000 | 25100 | 4550.0000000000000000 | 5 personnel | fi | 2 | 3900 | 3700.0000000000000000 | 7400 | 4550.0000000000000000 | 1 personnel | fi | 5 | 3500 | 3700.0000000000000000 | 7400 | 4550.0000000000000000 | 2 sales | se | 1 | 5000 | 4866.6666666666666667 | 14600 | 4950.0000000000000000 | 1 sales | se | 3 | 4800 | 4866.6666666666666667 | 14600 | 4950.0000000000000000 | 2 sales | se | 4 | 4800 | 4866.6666666666666667 | 14600 | 4950.0000000000000000 | 3 (10 rows)
Like CTE, window functions is a feature specified in the SQL standard, but it’s not supported by all OSS or proprietary RDBMS systems.
Pivoting data
Sometimes it’s nice to be able to pivot data in a properly normalized data model, so that repeating groups of related entities are folded into parent entity as columns. This can be useful e.g. for reporting purposes and ad-hoc queries. PostgreSQL can handle pivoting data using subqueries and arrays like this:
mydb=> SELECT e.*,
mydb-> (SELECT ARRAY_TO_STRING(ARRAY(SELECT emp_phone_num FROM emp_phone p WHERE e.employee_id = p.emp_id), ',')) AS phones
mydb-> FROM employees AS e;
employee_id | last_name | manager_id | phones
-------------+-----------+------------+-------------------------
100 | King | |
101 | Kochhar | 100 | 555-123,555-234,555-345
108 | Greenberg | 101 | 555-111
205 | Higgins | 101 | 555-914,555-222
206 | Gietz | 205 |
...
(13 rows)
Another way is to use the tablefunc extension module again:
mydb=> SELECT *
mydb-> FROM crosstab(
mydb(> 'SELECT emp_id, contact_type, contact FROM emp_sm_contact ORDER BY 1',
mydb(> 'SELECT DISTINCT contact_type FROM emp_sm_contact ORDER BY 1'
mydb(> )
mydb-> AS emp_sm_contact(emp_id BIGINT, "g+" TEXT, "linkedIn" TEXT, twitter TEXT);
emp_id | g+ | linkedIn | twitter
--------+-----------+-----------+---------
100 | bking | b.king | beking
101 | kochhar.2 | kochhar.1 | kochhar
200 | | | whalen
(3 rows)
Other advanced features
Other advanced PostgreSQL features that I find of interest to application developers include:
- pattern matching. Regular expression matching is supported
- geolocation queries. PostGIS extension adds comprehensive support for managing and querying geospatial data
- partitioning
- replication
Final thoughts
Problems faced in the transition phase of the software development process, when the software has been handed over from development to operations team, have prompted the need for closer collaboration between the teams in the form of devops culture. Similarly, application developers can’t remain ignorant of database design, implementation and optimization issues, and expect the DBAs to magically fix any data tier related design issues after the system has been implemented. Application developers need to learn how to leverage database systems effectively and take responsibility of database tier design to make transitions more seamless and production deployments succeed.
While standards based object relational mapping (ORM) technologies, such as Java persistence API, can be a great help to application developers, developers should be aware of what kind of queries the ORM implementation is generating, and in particular watch out for N+1 queries issues. With higher data, transaction volumes or data access patterns advanced database features will be a significant help in optimising the application.
To quote Oracle guru Tom Kyte: it’s a database, not a data dump
. PostgreSQL is an advanced relational database engine and it has a lot of features that can help application developers implement new features faster and in a more efficient and scalable manner. As with all the tools: you should learn how to use it to get the most out of it.
More info
- DDL, sample data and queries used in this blog entry, see file-advanced-psql-examples-sql
- PostgreSQL 9.2 documentation
Tomcat JDBC Connection Pool
Posted by on 2013-03-29
tomcat-jdbc is a relatively new entrant to the Java JDBC connection pool game. It’s been designed to be a drop-in replacement for commons-dbcp.
Many of the popular Java connection pool implementations have become quite stagnant over the years, so it’s nice to see someone make a fresh start in this domain. tomcat-jdbc code base is small and has minimal dependencies. It has configurable connection validation (validation policy, query and intervals) and enables automatically closing connections after they reach a configurable maximum age.
Some time ago, we started having problems with a near end-of-life legacy application that was migrated to a new environment. The application was a standalone Java app that used commons-dbcp as its JDBC connection pool implementation. After the migration, MySQL connections started failing occasionally. This appeared to happen with a somewhat regular interval of a few hours. Since tomcat-jdbc API is compatible with commons-dbcp we were able to replace the connection pool without any code changes and configure the new pool to automatically close connections once they had been open for a certain period of time. This turned out to be an effective and nonintrusive workaround for the issue.
I hope the Tomcat development team would more actively promote using tomcat-jdbc also outside of Tomcat. The pool implementation doesn’t currently seem to be available as a separate download or from Maven central, which is likely to hinder its adoption.
A JVM polyglot experiment with JRuby
Posted by on 2013-01-21
The nice thing about hobby technology projects is that you get to freely explore and learn new things. Sometimes this freedom makes the project go off at a tangent, and it’s in those cases in particular when you get to explore.
Some time ago I was working on a multi-vendor software development project. We had trouble making developers follow Git commit message guidelines and asking multiple times didn’t help, so I thought I’d implement a technological solution for this. Our repositories were hosted at GitHub, so I studied the post-receive hooks mechanism, learned a bit of Ruby and implemented my own service hook that validates the message format against a configurable format, generates an email using a configurable template and delivers it to selected recipients. Post-receive hooks don’t prevent people from committing with invalid messages, but I chose to go with a centralized solution that would not require every developer to configure their repository. I submitted my module, test code and documentation to GitHub, but the service hook implementation was rejected.
After the dead-end, I decided to try enforcing a commit message policy using a server-side hook that could actually prevent invalid commits. That solution was technically viable, but as suspected, it turned out that not all developers were willing to configure the hook in their repository. Also, every once in awhile when developers do a clean clone of the repository, the configuration needs to be redone.
So, I decided to study how service hooks could be run on an external system instead of being hosted on GitHub. The “WebHook” service hook allows you to deliver the post-receive event anywhere over HTTP. GitHub also makes service hook implementations available to be run on your own servers. The easy way would’ve been to simply take my custom service hook implementation and run it on our server. In addition to being too easy, there were some limitations with this approach as well:
- a github-services server instance can only have a single configuration i.e. you can’t serve multiple repositories each with different configurations
- the github-services server dispatches data it receives to a single service based on the request URL. It’s not possible to dispatch the data to a set of services.
- you have to code service hooks in Ruby
I had heard of JRuby at that time, but didn’t have practical experience with it. After some experimenting I was able to validate my assumption that GitHub Service implementations could, in fact, be run with JRuby. At that point I started migrating the code base into a polyglot GitHub Services container that allows you to run the GitHub provided github-services as well as your own custom service implementations. Services can be implemented in different languages and run simultaneously in the same container instance. The container can be configured with an ordered set of services (chain) to handle post-receive events from one or more GitHub repositories. It’s also possible to configure a single container with separate service chains, each bound to a different repository. The container is run in Jetty servlet container and uses JRuby for executing Ruby code.
Below is an illustration of an example configuration scenario where two GitHub repositories are set up to deliver post-receive events to a single container. The container has been configured with a separate service chain for each repository.

The current status of the project is that a few GitHub Services as well as my custom Ruby and Java based services have been tested and seem to be working.
Lessons learned
The JVM can run code written in a large number of different programming languages and it’s a great platform for both dynamic language implementers and polyglot application developers. To quote JRuby developer Charles Nutter:
The JVM is going to be the best VM for building dynamic languages, because it already is a dynamic language VM.
Java 7 delivered vastly improved support for dynamic language implementers with JSR 292 or the invokedynamic bytecode instruction. Java 8 is expected to further improve language interoperability and performance.
JRuby is an interesting alternative Ruby implementation for the JVM. It’s mature and the performance benchmark numbers are impressive (Why JRuby) compared with Ruby MRI. Performance is expected to get even better with invokedynamic optimization work being done for Java 8.
While taking the existing Ruby based github-services and making them run on JRuby was successful and didn’t require any code changes, there were lots of small issues that took a surprising amount of time to resolve. Many of the issues were related to setting up the runtime environment in one way or another. High-level troubleshooting strategies are similar from platform to platform, but on a more detailed level the methods and tools are often quite different, and many of the problems I encountered might have been easier to crack with solid Ruby experience.
Here’re some lessons learned during the project:
- Learning how to use the JRuby embedding API. There’re 3 different APIs to choose from: Red Bridge, JSR 223 and BSF. Performing tasks like instantiating objects and passing parameters in a Java call-out was not immediately obvious at first using Red Bridge
- Figuring out concurrency / thread-safety properties of different areas of the JRuby embedding API. JRuby concurrency documentation was lacking at the time when the project was started.
- JRuby tooling. Tooling works somewhat different from Ruby.
- bootstrapping GitHub services gem environment 
- in order to keep the github-services installation self-contained, I wanted to install as many gems as possible in the github-services vendor directory instead of installing them in JRuby. Some gems had to be installed in JRuby while others could be installed in vendor tree.
- some gems need to be replaced by JRuby specific ones (e.g. jruby-openssl)
- setting up Ruby requires and load paths
- Gems implemented as native extensions require a compiler toolchain as well as gem module library dependencies to be installed.
- bypassing the Sinatra web app framework that’s used by github-services
Probably, most of the issues I encountered were related to bootstrapping GitHub services gem environment in some way.
Code for the experiment can be found from https://github.com/marko-asplund/github-hook-jar
JavaOne 2012 – Technical sessions
Posted by on 2013-01-20
While trying to find information about technical sessions presented in JavaOne 2011 and earlier I noticed there was surprisingly little details available. Many of the results I got from googling were pointing to the JavaOne 2012 site or the links were broken. So, even though it’s been a while since the conference, I thought I’d post some notes about the themes for historical reference.
The technical sessions (487) were classified in the following tracks:
- Core Java Platform (146 sessions)
- Development Tools and Techniques (212 sessions)
- Emerging Languages on the JVM (44 sessions)
- Enterprise Service Architectures and the Cloud (112 sessions)
- Java EE Web Profile and Platform Technologies (123 sessions)
- Java ME, Java Card, Embedded, and Devices (62 sessions)
- JavaFX and Rich User Experiences (70 sessions)
The numbers were from Oracle’s Schedule builder application.
Some of the hot topics in JavaOne 2012 were thin server architecture, REST, HTML 5, NoSQL, data grids, big data, polyglot, mobile web and cloud. There was also a lot of interest on next big things on the Java platform roadmap, especially Java SE 8 (Lambdas) and Java EE 7 related talks.
In addition to the new and exciting topics, the evergreen topics such as troubleshooting and optimization (esp. garbage collection), scalability, parallellism, design and design patterns seemed to draw a lot of attention.
Java on Mac OS X
Posted by on 2013-01-03
Mac OS X is a nice platform for Java development because it successfully combines a very good desktop user experience with the system’s unix heritage and tooling. There are some problems, however:
- only a limited set of JDK versions are available for current OS X releases
- the JVM implementations are not standalone and require Apple proprietary frameworks to be present
In this respect, Linux is probably the best Java development platform because JDKs are available from many different vendors and multiple versions of the most popular JDKs run on Linux. The JVM implementations, usually don’t have esoteric dependencies and only require basic OS libraries in addition to the ones bundled with the JVM.
On the other hand, only Apple and Oracle provided JDKs run on Mac OS X and older Java versions aren’t available. Also, neither Apple’s Java 6 nor Oracle’s Java 7 JVM seems to run on Lion or Mountain Lion without the com.apple.pkg.JavaEssentials package, for example.
Recently, I managed to corrupt my Java installation beyond repair and I wanted to try and avoid this in the future by trying to isolate my Java 7 and 8 installations as much as possible. This turned out to be fairly simple if you defy the temptation to install by just clicking on the downloaded JDK package. The JDKs are distributed by Oracle as disk images that contain a Mac OS X installer package file. Instead of running the installer you can easily extract the contents of the package using command line tools. First mount the disk image by clicking on the disk image and then run the following commands in a terminal session:
xar -xf '/Volumes/JDK 8/JDK 8.pkg' cat jdk180.pkg/Payload | gunzip | cpio -i
After that, the Contents directory will include the entire JDK installation and you can move it to the location of your choosing. Then just specify JAVA_HOME environment variable and add the JVM and required tools to shell search path.
JavaOne 2012 – Keynotes
Posted by on 2012-11-16
Java Strategy Keynote
Java Strategy and JavaOne technical keynotes were delivered at the end of the first conference day, on sunday.
The Java Strategy keynote was kicked off with a “catchy” music video “coding in Java”. After the video Hasan Rizvi, EVP Middleware and Java Development, opened the more formal part of the keynote. Rizvi described how the conference theme “make the future Java” referred to two different aspect of building the future:
- a) ensuring the platform stays competitive. Competitiveness involves platform completeness, modernization and innovation, developer productivity as well as quality and security
- b) making sure that the collaborative process through which the platform is being developed, works well. The process needs open and transparent evolution, and active community involvement
Rizvi noted that “we have bet our business on Java and a lot of you have bet your business and careers on Java”. Oracle’s Fusion Middleware platform as well as a lot of (if not all) Oracle applications have been built on Java, so Oracle has in fact, made a huge bet on Java.
As for the Java roadmap, Oracle stated they’re committed to more regular platform major releases. During Sun stewardship there was a period of Java stagnation when 4.5 years elapsed between Java 6 ja 7 releases, and Java 7 was actually finally released by Oracle, not Sun. Even though evolving Java is a collaborative effort, a lot of responsibility lies on the steward. A key duty is to produce the reference implementation. The developers, partners, clients and all the stakeholders in the Java ecosystem need to be able to rely on the steward to move things forward in a consistent and predictable manner, and timeboxed releases are an important indication to everyone that the train is moving.
Rizvi gave some highlights of Java roadmap for SE, ME, EE, JavaFX, Java Card and NetBeans. These were later described in more detail by the product development leaders. He also presented results for Oracle’s Java 2012 scorecard. The scorecard is split into three different areas: technology, community and Oracle leadership.
Rizvi then handed over to Georges Saab, VP / Development who described the current state of Java SE 7 adoption. According to Saab they’re seeing rapid uptake of the new release and mentioned that Oracle supports its entire Fusion Middleware stack on JDK 7. (With the end of public Java 6 updates scheduled for 2013 february, it’s time to upgrade unless you have a Java support contract.) He also emphasized support for 2 new platforms added in the release. Support for Linux ARM seems very much related with Oracle’s aspirations for Java in the embedded space (Saab mentioned the emerging ARM microserver market).
Java 8 is scheduled for Q3 2013 with developer preview slated for February 2013. OpenJDK 8 early builds are available already to test things like Lambda. Some of the highlights of the planned release content include Lambda expressions (closures), parallel operations on core collections API, eliminating PermGen, a new JVM based JavaScript implementation called Nashorn, language interoperability, Java ME/SE convergence and new Date & Time APIs. Oracle is planning to contribute Nashorn to the OpenJDK project. Nashorn is said to be a high performance, modern JavaScript implementation on the JVM and will probably replace the experimental Rhino JavaScript engine shipped since JDK 6. NetBeans uses Nashorn internally for its JavaScript support.
Java 9 will likely include at least Jigsaw modularity, which was deferred from Java 8 and is scheduled for 2015. While some potential development areas were listed for this release the details were pretty scarce, as can be expected at this time.
Nandini Ramani, VP / Engineering, Java Client and Mobile Platforms, then took to the stage to describe plans for Java Client and Embedded. It’s interesting to note that JavaFX is not currently supported on all Oracle supported Java platforms, which would in theory seem to contradict the “write once, run anywhere” proposition. Ramani was briefly joined by people from Navis and Canoo to present a JavaFX in cargo management case study.
Then back to longer term plans for the JDK. Phil Rogers of AMD described Project Sumatra, which aims to bring heterogeneous computing platform to Java. Rogers described the hardware trends behind the project:
1) first the move from single core to multi-core CPUs and now to 2) full SOCs (system on chip) and a heterogeneous computing platform, where we combine a CPU and the parallel processor of the GPU into a single piece of silicon and shared memory
High level of parallelism is required from the platform by workloads such as media processing, AI, and big data. With Sumatra developers will be able to write code that will take advantage of the heterogeneous computing platform without explicitly coding for it. The JVM will decide on runtime whether to run the code on CPU or GPU.
Ramani then came back to tell about Java in the Embedded space. I’ve written another blog entry about this, so I won’t go into detail here. It was interesting to note, however, that Oracle seems very determined to push Java in the embedded space and they’re talking a lot about the “Internet of Things” and M2M communication. In Java Embedded their focus seems to be on small headless devices, which apparently doesn’t include smart phones. They also want to lower the barrier of entry for a Java SE developer to enter embedded development through Java ME / SE convergence mentioned earlier. This could create interesting opportunities for developers by allowing them to move between these ecosystems. Java ME / SE convergence appears to be a key driver behind JDK 9 modularization (Jigsaw). Ramani concluded her part of the keynote by introducing two more case studies: Java enabled SOC by Cinterion (Java Embedded) and MintChip by The Royal Canadian Mint (Java Card based digital currency).
Cameron Purdy, VP Fusion Middleware Development and Java EE, took to stage after Ramani to discuss Java EE status and direction. He started off by briefing on Java EE 6 adoption among application developers and JEE server vendors. He then went on to describe Oracle’s Java EE focus areas that include standardization, productivity, portability, extensibility and modularity. Like other keynote speakers, Purdy also emphasized that developing the Java EE platform and specifications is a community effort. He presented some interesting details about Java EE release dates, themes and number of specifications included up to Java EE 7. Java EE 7 is currently scheduled for Q2 2013. The release themes include HTML 5 and continued developer productivity. Features such as WebSockets, Servlet 3.1 NIO, Server Sent Events, JSON, REST are considered to fall under the HTML 5 theme umbrella while API pruning, built on Java SE 7, JCache, JMS 2.0 and batch are driven by the productivity goal. Some features that Oracle would like to see in Java EE 8 were discussed briefly, but it will be the responsibility of the eventually formed expert group to decide what will go into the actual specification. Cloud programming (multitenancy for SaaS apps, PaaS enablement) model standardization was a feature deferred from Java EE 7 and will likely be included in JEE 8. Other things being considered include NoSQL, Project Avatar, state management, JSON-B and modularity based on Jigsaw. Purdy finally invited Nicole Otto from Nike to endorse Java EE as the platform for Nike’s online services.
In the final part of the keynote, Robert Ballard, oceanographer and discoverer of RMS Titanic, talked about innovation and science education. He described how modern oceanography makes pretty advanced use of information and communications technology. He told he’s often asked what he’d like to discover next? A spaceship, he said. Why? Because then I’d never have to talk about the Titanic again 🙂
IBM Keynote
IBM was a diamond sponsor for the conference and they presented their own keynote, right after the strategy keynote. The IBM talk focused a lot on cloud enablement and optimization, multitenancy, tenant isolation and reducing footprint. Polyglot also appears to be on IBM’s Java platform agenda as they discussed support for multiple JVM-based languages. A key part of IBM’s message was that hardware matters. Even if Java developers typically work at a level where the underlying hardware is abstracted away, system hardware architecture design is still crucial for mission critical applications. Somewhere deep below all the layers of indirection, hardware virtualization and JVM simulated virtual machine, the code is still run by physical processors. And since IBM can deliver the whole stack from server hardware and storage to language runtime and middleware, all the pieces have been designed and optimized to work together. So, IBM was basically echoing the Oracle “software and hardware, engineered to work together” -value proposition. They also presented SPECjEnterprise and SPECpower_ssj2008 performance performance benchmark figures where the IBM J9 JVM came out as the winner.
Java Technical Keynote
The Technical keynote was primarily delivered by Oracle Java Platform Chief Architect, Mark Reinhold. The technical keynote focused on Java SE (Java 8) and Java EE (JEE 7) platform releases. These releases were presented against the backdrop of sample applications (Schedule builder and Angry bids). Java Language Architect Brian Goetz dropped by on stage to show how Java 8 Lambda together with changes in the collections API can make the JavaFX Schedule builder application code more beautiful, and improve code and libraries in general. A large part of the presentation was dedicated to Jigsaw, which I think will play a really big role in the future of the platform. Jigsaw will not be included in Java 8 but Lambda, compact profiles, Nashorn, data/time API and type annotations will. In addition, various smaller things like PermGen removal, bulk data operations, parallel array sorting etc. are also scheduled for Java 8.
Arun Gupta, Java EE Technology Evangelist, then talked about Java EE in more detail than in the strategy keynote. Gupta briefly talked about Java EE history and current status in terms of release dates, release theme and dates. He then dived deeper into the Java EE 7 specification content. Some of the more interesting current candidate specification requests for Java EE 7 include: JAX-RS 2.0, EL 3.0, JMS 2.0, Java Caching API, Java API for JSON and Java API for WebSocket. Many other EE specifications will also get smaller updates such as JTA, EJB, CDI and JPA. After more than ten years in the making, who would’ve thought the Caching API specification would actually get finished some day 🙂 I was happy to see that EE 7 will not only bring additions to the specification, but will also remove things by making some APIs optional. The idea of pruning was introduced already in EE 6, so it’s not new, but it’s good to see the cleanup process continuing. Gupta then moved to detail changes to selected EE sub-specifications and demonstrated how the updates would improve productivity and reduce boilerplate code.
Thin server architecture is still an emerging architectural model for designing web applications that moves view generation from the server-side to the client side. Thin server architecture is platform agnostic and it effectively moves a lot of server-side code to the browser side that has traditionally been the domain of front-end or web developers. As the name implies, the server-side gets a lot simpler and thinner, and with this change, in my opinion, comes a really big productivity challenge for developing the Java backend wrt. to dynamic languages. Project Avatar and Easel are projects that are tackling this problem and exploring what kind of infrastructure and tooling is required end-to-end to build TSA applications on the Java platform. Some of the tooling is already available in NetBeans 7.3 beta, so it’s something that can be tried out right now. A TSA sample application called Angry bids, as well as the tooling part for developing the app were demoed.
Java Community Keynote
The Java community keynote was scheduled for the last day of the conference and started off with lots of thank yous and some making waves. After that, Gary Frost of AMD was brought up by Donald Smith (Oracle) to discuss Project Sumatra that was mentioned earlier in the Java Strategy keynote. AMD has been working to make it possible for Java developers to take advantage of the GPU for a few years now, and they’ve released an open source project called Aparapi for doing this. Aparapi requires that code be specifically written to get it executed on a GPU, but Sumatra aims to make all this unnecessary. Frost showed some interesting demos of rendering a Mandelbrot set, Game of life and N body physics simulation using Aparapi. Frost said AMD is hoping to get Sumatra included in the JDK within Java 9 timeframe.
Smith then reflected on the role of Java in innovation. His approach was to separately mindmap the strengths of Java and fostering innovation, and try to see how these two could be linked together. He invited people from Eucalyptus, Twitter, Cloudera, Eclipse and Perrone Robotics for a panel discussion on the role of Java in innovation.
After the innovation panel, Martijn Verburg of London JUG, introduced the Adopt a JSR -program they had started. The purpose was said to be to prevent bad specifications, such as EJB 2.0, from happening again by engaging ordinary developers in the specification process. Verburg hosted a short panel where he asked the panelists a range of questions related to their role in the Java community and Java specification process.
After the panel Saab brought up Paul Perrone to discuss and demo a Java based robotics platform his company develops. Continuing on the robotics theme, Java creator James Gosling came up on stage wearing his Sun Microsystems t-shirt to tell about his current work at Liquid Robotics, and how they’re using Java. Liquid Robotics is building robots that float in the ocean and gather telemetric data of different kinds for various purposes (e.g. marine mammal and pollution tracking, weather data, global warming studies etc.). Java is used for analysing the data delivered by the robots, but also the newer robot generation has an ARM processor and runs JDK 7 on Linux (ARM). They’ve built a Swing based UI for studying and drilling down the data, e.g. the routes that each robot has travelled. Gosling had evaluated all of the NoSQL databases for his use cases but felt that no existing ones worked well with the telemetry data they process, so he built his own NoSQLish database. The data they receive is really valuable, so reliability is crucial, which is why they’re using 3 different hosting providers. After evaluating hosting providers he confessed to be a real Jelastic fan. So, since Gosling in his role as the chief software architect in his new company picked to build on Java and chose to present at JavaOne, I guess it means he still has a soft spot for the platform.
Conclusions
Oracle is a huge company and many people in the developer and OSS communities have had reservations about what will happen to Java under Oracle leadership, and whether Java will be submitted to its owner’s short-term commercial ambitions. But despite its huge size Oracle is not self sufficient and their long term success is very much tied to the larger developer ecosystem. This means that Oracle needs to make sure Java is a platform that developers want to invest their human capital in also in the future.
Active community participation is absolutely vital for Java’s long term viability and it’s reassuring to see that Oracle seems to acknowledge and commit to this. Recent changes in the Java Community Process (JCP), that governs the rules for creating Java specifications, require a more open and transparent way of working from the expert groups. By making OpenJDK the Java SE reference implementation (RI), Oracle has leveled the playing field with regard to other Java SE vendors, as now Oracle’s Java implementation is only one Java SE implementation among others that has to conform to the specification and RI. Oracle has also been able to engage IBM in OpenJDK instead of Apache Harmony, which I think overall will be reduce the risk of fragmentation and benefit the whole Java community.
According to the Java Community Process, the specification lead of a particular JSR is responsible for developing the specification, but also for producing a reference implementation as well as Technology Compatibility Kit (TCK or test suite). For large specifications, such as Java SE and EE, this is no small task. OpenJDK is the Java SE reference implementation while GlassFish is the Java EE RI. There’s been some speculation about whether the JDK will remain to be made freely available, as well as the future of some Sun Java products, such as GlassFish and NetBeans, under Oracle leadership. OpenJDK and GlassFish have a clear role to play in this picture as platform reference implementations. NetBeans on the other hand provides support for emerging technologies and day 0 support for new Java standards, which is important for allowing developers to actually get hands-on experience with new standards. So, currently none of these products would appear to be redundant.
Traditionally ME and SE/EE development were regarded very different and were typically performed by people with different skill sets. The plan for ME / SE convergence on platform and API level could change that in the short term (Java SE 8 timeframe). Also, with the merge of previously separate JCP executive committees for ME and SE taking place in november, work is being carried out in the process level to try and avoid the platforms from diverging in the future.
Google used to be a visible and active member of the Java community before the legal dispute between Google and Oracle started over Android. Google has also released quite a few interesting Java based components as open source so, it’s been a pity to see Google withdraw from JavaOne as well as many other Java communities. No googlers appeared to be presenting at this year’s JavaOne either. I was surprised to find out after the conference (through some googling) that Google is actually still a member of the JCP Executive Committee and they’ve also joined the Java SE 8 expert group in August 2012! Hope they will be able to have a more active role in the Java ecosystem in the future.
There’re a lot of interesting technology changes planned for Java. Some of the changes I’m really looking forward to include
- JDK modularization (via Project Jigsaw, JDK 9)
- thin server architecture support (via Project Avatar and Easel, NetBeans v7.3, Java EE 7 / 8)
- Java SE / ME convergence (JDK 8)
- compact profiles (JDK 8)
- heterogeneous computing platform support (via Project Sumatra, JDK 9?)
Many enhancements and changes that are clearly driven by polyglot requirements appeared on Oracle’s tentative roadmap plans, so they seem to be serious about improving polyglot support in the JVM.
Based on the conference and actual work being carried out by Oracle and the larger Java community, I think Java will remain viable as a community, technology platform and an ecosystem.
